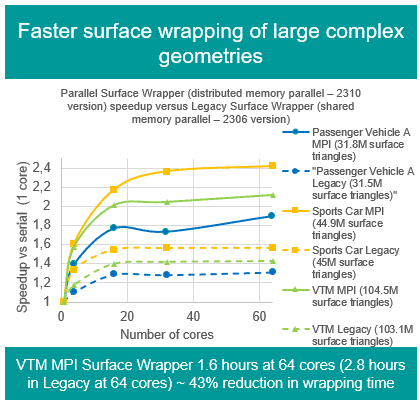
A Design Of Experiments (DOE ) is typically used to explore the variation of input parameters and the response. The variation can be randomized, but is often more efficient with systematic sampling. DOEs are for instance often used for local exploration around a particular optimized design to identify the parameters that have the greatest impact on the performance. You can also assess the sensitivities of the input parameters and their interaction with each other.

The Design Manager in Simcenter STAR-CCM+ comes with the DOE study type which allows you to use different statistical methods for generating near random samples. The DOE is available with the Intelligent Design Exploration add-on. But can you set up DOE if you don´t have access to the additional license option?
In the following we will discuss the options to set up a random sampled Manual Study and compare this with a DOE Study. To quantify the performance, we compare cross validate of Surrogate Models which were created on the samples.
Surrogate Methods have been introduced to Simcenter STAR-CCM+. They can readily be created on every Design Study as by-product. With discrete data samples you can train the fitting function. The quality of the response surface fit depends strongly on the underlying information. What you want is an evenly distributed set of design samples to map your design space, yet with the smallest possible number of samples to save resources. In other words, what you need is a DOE (Design Of Experiments).
Random sampled Manual Study with Excel
In Design Manager, that comes with no additional license to Simcenter STAR-CCM+, we can set up Parameter Sweeps and Manual Studies. Here we focus on Manual Studies because a Manual study allows you to automate the process of running a collection of specific designs. You can define a set of designs using tabulated data, where each design is a certain combination of input parameter values that you prepare outside of Simcenter STAR-CCM+ before starting the analysis.
Since you most likely have access to Microsoft Excel, this is the free lunch in our comparison. Excel offers build in randomized sampling methods. Of which simplest is the RAND() function. The RAND function creates a random number between 0 and 1. Like a value of your parameter, normalized with the upper and lower limit. Reverse the normalization and you´ll get the absolute parameter value.
![]()
The second sampling method option in Excel is the Analysis ToolPak addd-on. The Analysis ToolPak is an additonal set of options for certain statistical functions in Excel. Once activated (File > Options > Add-ins) Data Analysis button appears in Data tab:

The input for this sampling method is specific data you are interested in (original population). For instance, a resolution of your search space by incrementing from min to max with . The sampling methods selects randomly from the original population.
. The sampling methods selects randomly from the original population.
With both methods you can randomly create data for multiple parameters and combine these to describe design variants in your design space. Export the newly created data to a comma separated CSV file. In some cases systems setting prohibit comma separation and CSV file are still generated with semicolons. Check your CSV file in a text editor because STAR only allows for comma separated CSV files.

Import the CSV file to your Manual Design Study after you selected input parameters. The column names must be identical with your parameter names. Now you created a Manual Study with randomized parameters.

DOE Study with Intelligent Design Exploration
If you have Intelligent Design Exploration add-on you can generate all data inside the Design Manager. 3 Sampling methods are available:
- 2 Level Full Factorial
- 3 Level Full Factorial
- Latin Hypercube Sampling
While the first factorial methods are very useful to evaluate all input parameters and their combinations to assess parameters effect, Latin Hypercube Sampling (LHS) generates samples with parameters values of a multidimensional distributions. And thereby covers the design space evenly.
A Latin Hypercube Sampling (LHS) DOE study evaluates a specified number of designs m. The input parameters are defined in the same manner as for a Sweep study as constant, discrete, or continuous. For a continuous parameter, lower and upper bounds limit the range of the parameter values. The resolution of the parameter equals m. When the analysis starts, the LHS algorithm combines the input parameters with each other in a way that maximizes the minimum distance between the generated design points. This promotes an even distribution of the designs points over the design space.

Surrogate assessment
To test the differently created surrogate models, we utilise the Simcenter STAR-CCM+ Tutorial Surrogates: Reliability of an Industrial Exhaust System. This is a multi-objective test case with 7 input parameter. We generate 1 DOE Study and two Manual Studies for the Excel generated samples:

In all cases we use the same input parameters and number of design (90). In the figure below, we exemplify the sampling on two input parameters (Bottom Angle Path [81.0, 87.0] deg and Deflector Angle [93.6, 100.4] deg).

For the Excel sampling method, each variable range is divided in 100 samples from which the sampling chooses values randomly. It is obvious that we get several clusters with similar parameter values for the RAND method. However, even if we can avoid clustering with the second method, we still get some white spots in the design space. To assess if these cluster have an impact on the quality of generated surrogate models, we judge the Cross V residuals.
When engineers create a surrogate model, there are different judging criteria used to evaluate the surrogate model fit. One of the judging parameters is Cross V residual value especially useful when RBF or Kriging methods are used to create the surrogate model. Cross validation tests predict accuracy by putting aside some of the known designs and then test the surrogate on the out-of-sample data.
For each removed design, Design Manager uses the reduced surrogate to estimate the response at the removed design and compare that to the actual response value. The difference is the cross-validation residual, which can be used to compare surrogate predictions and gauge surrogate accuracy. In our case is the Cross V of the surrogate for the Velocity_Uniformity lowest for sampling with LHS. Excel RAND function shows the highest residuals which correlates well with the observed clustering.

Final words or: How good is the free lunch?
We present an alternative, license free, method to create random sets of samples in Design Manager by loading Excel generated data into a Manual Design Study. The sampling is quantified by cross validating a Surrogate Model trained with the data. The results show that Latin Hypercube sampling is superior to both Excel methods. With the Excel Sampling you can better control your samples than with the RAND function and can create a design set well distributed in the design space.
Importing manually created design sets is a free lunch with all its quirks and restrictions. But you can get your free trail of the Intelligent Design Exploration add-on by contacting us at Volupe!
The Author
Florian Vesting, PhD
Contact: support@volupe.com
+46 768 51 23 46